![]()
What is Converser?
This is a simple python command line package which allows you to assess presentations & speeches which you record in audio format. A full breakdown of the input parameters required and output files generated is outlined in the README.md file GitHub Link
The Analysis Behind The Scenes
When you use Converser, you’ll receive a comprehensive analysis of your speech. Here’s what is goes on under the hood:
First, a full transcript of your speech is generated using OpenAI’s Whisper large model, which was trained on over 5 million hours of labeled audio data. This forms the basis for assessing several key metrics outlined below:
- Word count per minute: How quickly you speak.
- Mean pitch (when speaking): Your average vocal pitch during your spoken segments.
- Pitch standard deviation (between words): The variation in your pitch as you speak.
- Mean pause length: The average duration of your silences.
- Mean pause standard deviation: The consistency of your pause lengths.
- Use of filler words: Identification of common filler words like “like,” “er,” and “um.”
- Lexical diversity: The richness and variety of your vocabulary.
- Readability: Assessed using the Flesch-Kincaid test, which indicates how easy your speech is to understand.
Beyond these standard metrics, Converser leverages a couple other transformers (AI models) to provide deeper insights into the sentiment conveyed in your speech:
-
Sentiment Analysis (DistilBERT): This uses the distilbert-base-uncased-finetuned-sst-2-english model to analyse the overall sentiment of your transcript, classifying it as positive, negative, or neutral. This model is a lightweight, efficient version of BERT, specifically optimized for sentiment classification.
-
Emotion Analysis (DistilRoBERTa): To detect specific emotions like joy, sadness, or anger in your transcript, we employ the j-hartmann/emotion-english-distilroberta-base model. This fine-tuned version of DistilRoBERTa, trained on datasets like GoEmotions, provides detailed emotion scores, offering a nuanced understanding of your emotional expression throughout the speech.
On top of the sentiment classification, Converser allows you to include your own labels which you want to assess / capture in your speech. By default, this is set to ‘Confident’ & ‘Uncertainty’ for me which I included to gauge tone of my speech. However this could be set to anything like ‘Sports’ or ‘Politics’ and Converser will apply a zero shot classification system to assign a confidence score to each label, between 0 and 1, with a higher score indicating the transcript is more likely to be classified as this. The Zero Shot classification model used is the facebook/bart-large-mnli model. This powerful sequence-to-sequence model is fine-tuned for natural language inference and can identify emotions without needing prior task-specific training. It works by by comparing the speech transcript against predefined labels, making it incredibly flexible!
The Output
So how to does Converser present its insights?
Well the main output of Converser is a HTML file which can be viewed in any browser. This should launch automatically on completion of the analysis! This is broken down into several sections as outlined below and provides a comprehensive analysis of your speech.
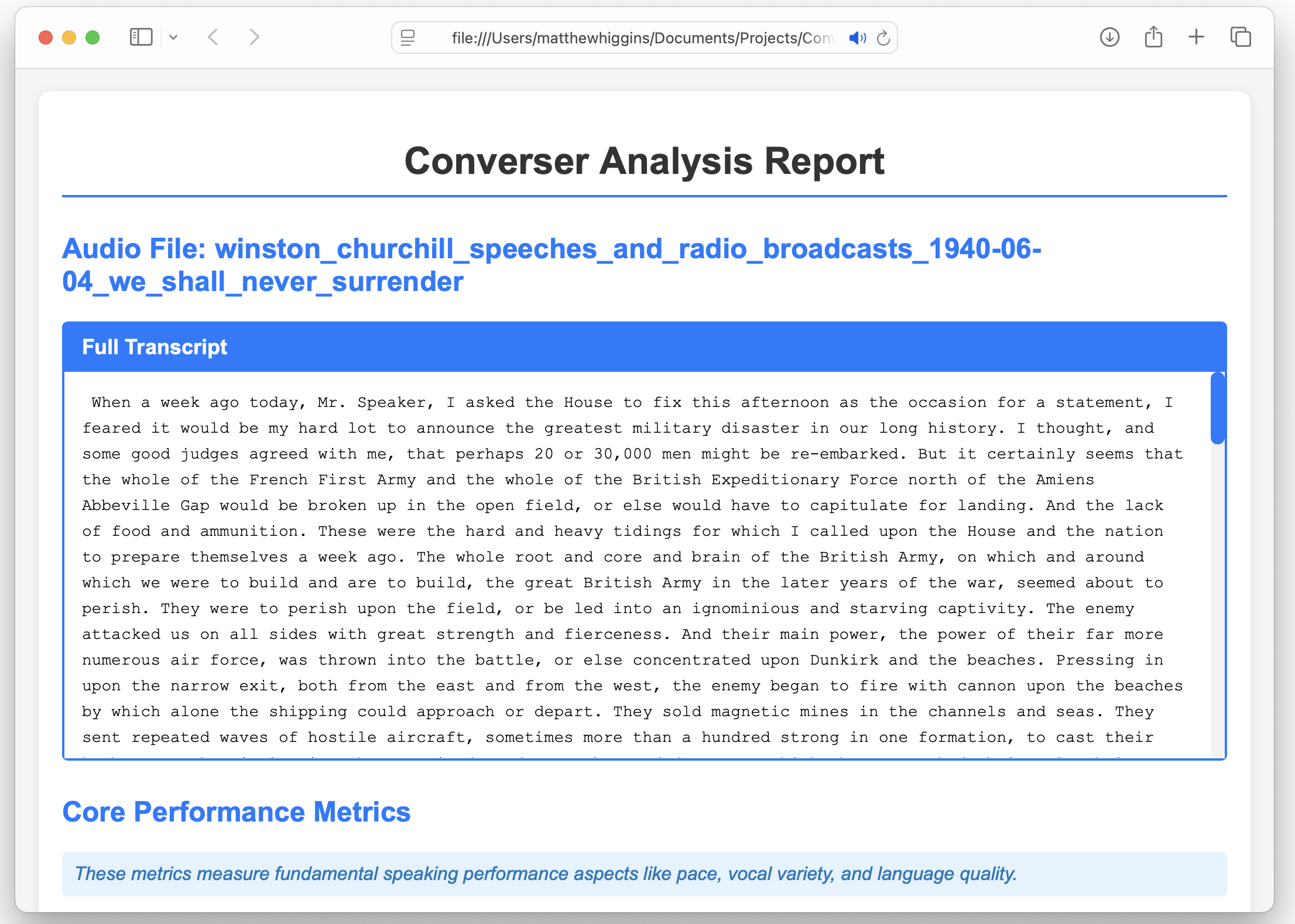
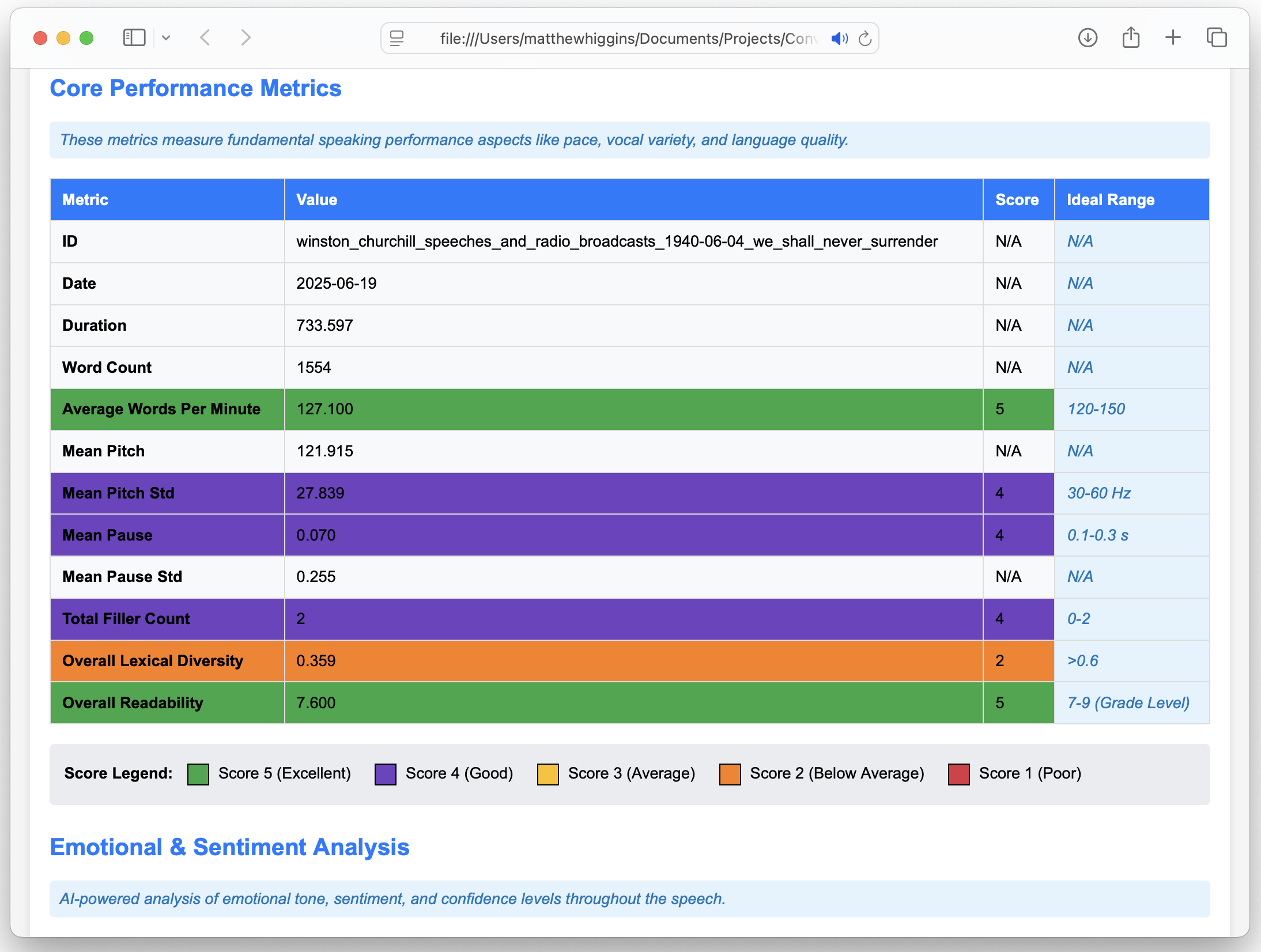
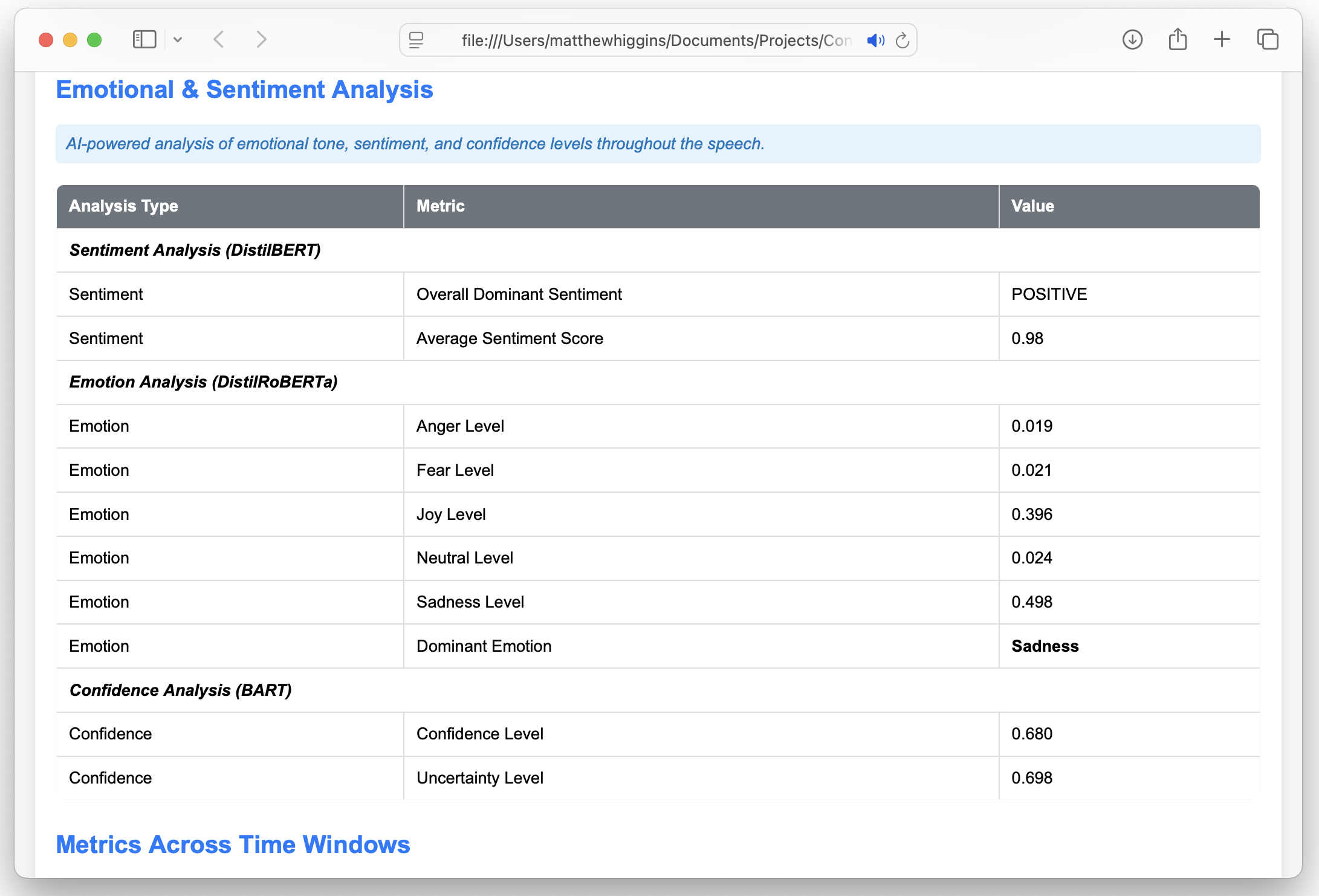
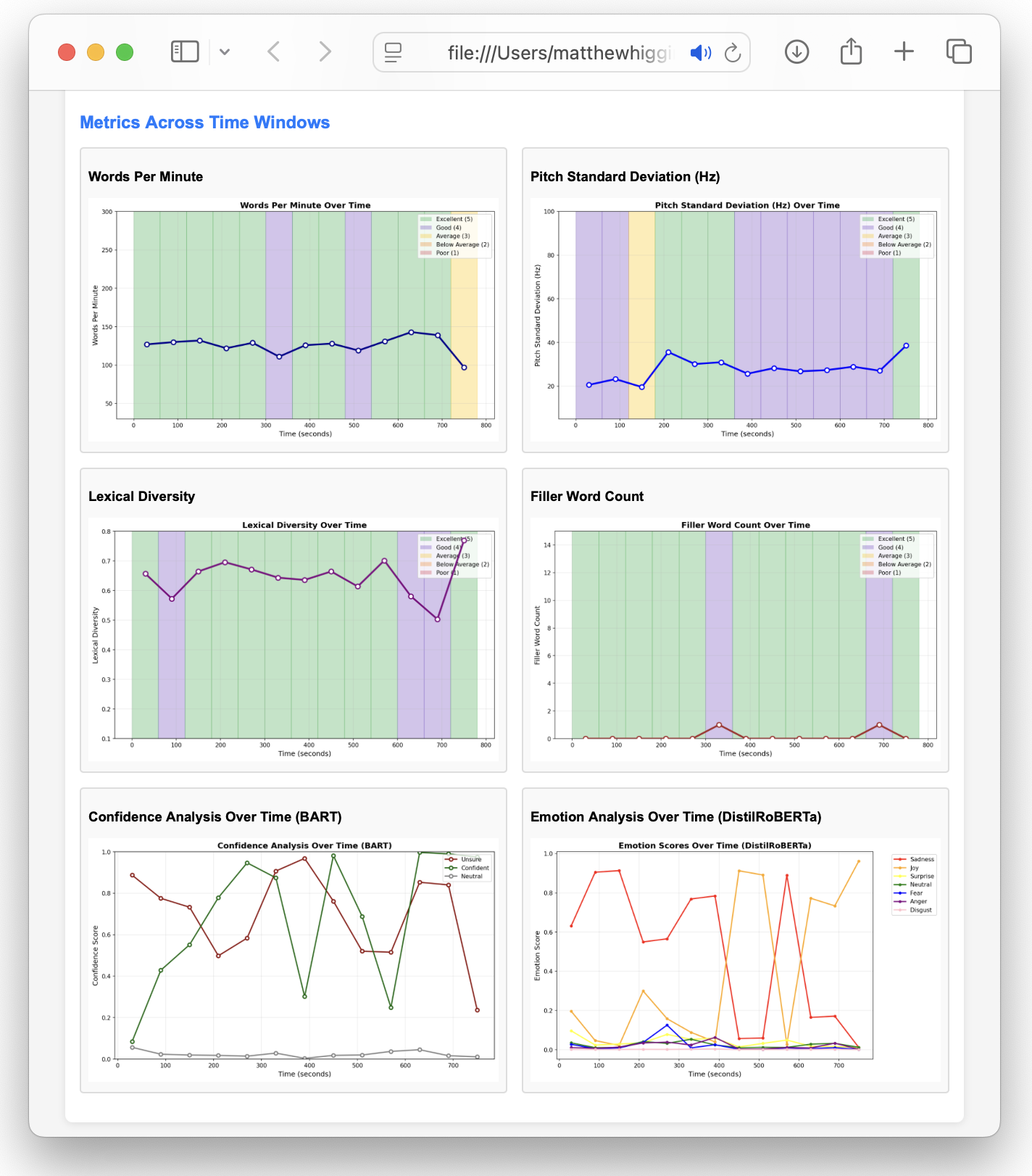
As you can see for some metrics these have been scored (1-5) and colour coded accordingly. The thresholds for each metric are outlined in the table below:
| Metric | Score 5 (Ideal) | Score 4 | Score 3 | Score 2 | Score 1 (Poor) |
|---|---|---|---|---|---|
| Average Words Per Minute (WPM) | 120–150 | 100–119 or 151–170 | 90–99 or 171–180 | 80–89 or 181–200 | <80 or >200 |
| Mean Pitch Variability (Hz std) | 30–60 | 20–29 or 61–70 | 15–19 or 71–80 | 10–14 or 81–90 | <10 or >90 |
| Mean Pause Duration (s) | 0.1–0.3 | 0.05–0.1 or 0.3–0.5 | <0.05 or 0.5–0.7 | 0.7–1.0 | >1.0 |
| Filler Word Count | 0 | 1–2 | 3–5 | 6–10 | >10 |
| Lexical Diversity (TTR) | ≥ 0.6 | 0.5–0.59 | 0.4–0.49 | 0.3–0.39 | <0.3 |
| Readability Grade | 7–9 (ideal range for general audience) | 6 or 10 | 5 or 11 | 4 or 12 | ≤3 or ≥13 |
Assessing The Greats!
To put Converser to the test I assessed two speeches from two great orators. These were the ‘I have a dream’ and ‘We Shall Fight on the Beaches’ speeches by Martin Luther King Jr and Winston Churchill, respectively. Understandably both speeches performed amazing well across all metrics and the example reports can be found at (https://github.com/MatthewHiggins2017/Converser/tree/main/Examples)
Final Note
If you would like to try Converser head to (https://github.com/MatthewHiggins2017/Converser/). I would highly appreciate any feedback for potential users and if you want to contribute just create a new pull request!
References
- Whisper Original Paper: https://arxiv.org/abs/2212.04356
- j-hartmann/emotion-english-distilroberta-base = https://huggingface.co/j-hartmann/emotion-english-distilroberta-base
- facebook/bart-large-mnli = https://huggingface.co/facebook/bart-large-mnli
- Deberta-v3-large-zeroshot-v2.0 = https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0 = https://arxiv.org/abs/2312.17543